To avoid significant noise amplification when the number of training data are small, an approach is to add an extra term (extra constraint) to the least-squares cost function.
- The extra term penalises the norm of the coefficient vector.
Modifying cost functions to favour structured solutions is called regularisation. Least-squares regression combined with l2-norm regularisaion is known as ridge regression in statistics and as Tikhonov regularisation in the literature on inverse problems.
In the simplest case, a positive multiple of the sum of squares of the variables is added to the cost function:
$$ \sum_{i=1}^{k}(a_i^Tx-b_i)^2+\rho \sum_{i=1}^{n}x_i^2 $$
where
$$ \rho>0 $$
- The extra terms result in a sensible solution in cases when minimising the first sum only does not

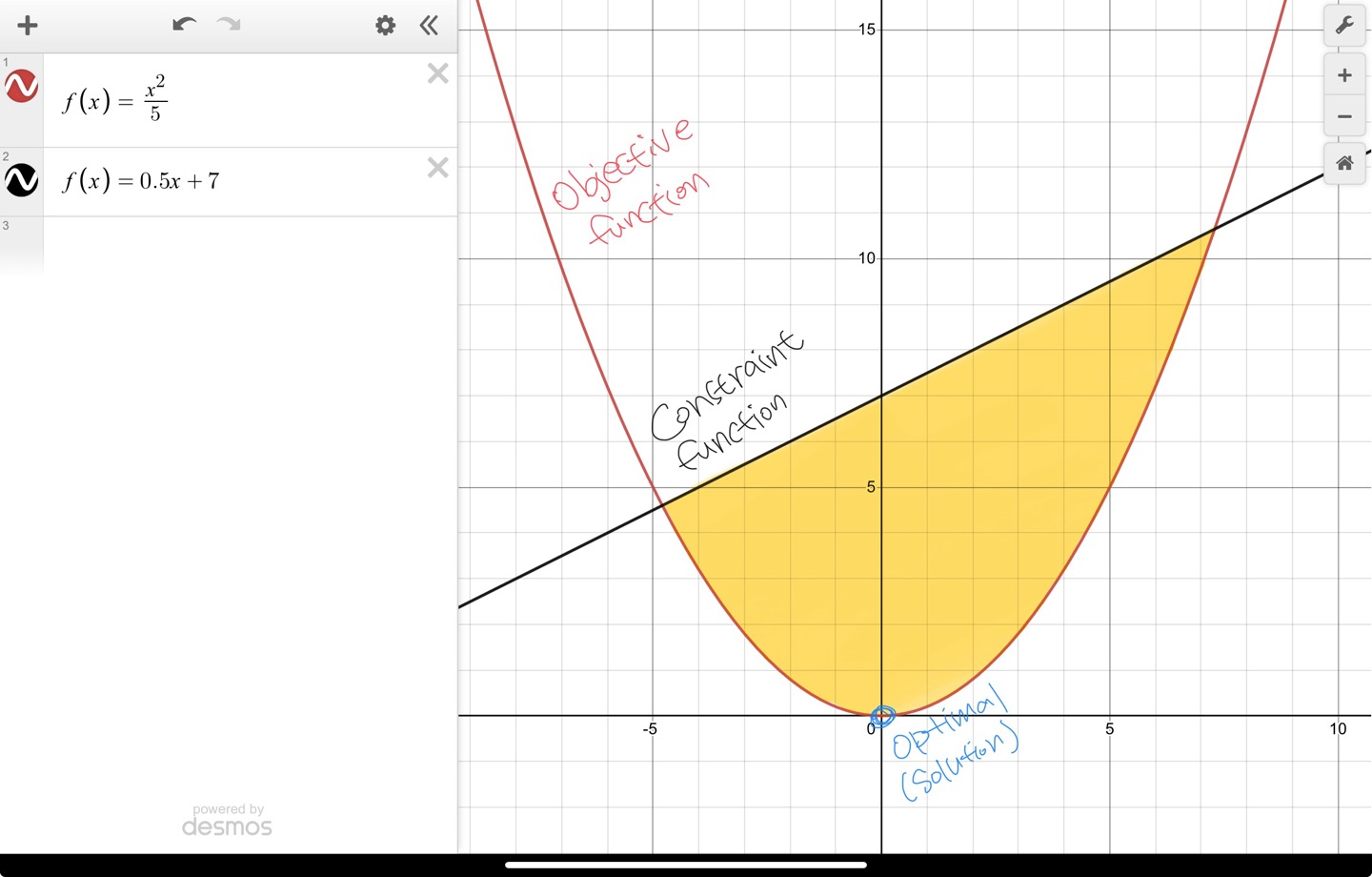
To refine the choice among Pareto optimal solutions, the objective function landscape can be adjusted by adding specific terms.
'MachineLearning > Optimisation' 카테고리의 다른 글
| Gradient Vector, Hessian Matrix, and Jacobian Matrix (2) | 2025.07.03 |
|---|---|
| SGD, ADAM, HN ADAM (3) | 2025.06.27 |
| Least-squares problems (0) | 2024.01.16 |
| Mathematical optimisation problem (basic concept) (0) | 2024.01.16 |