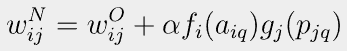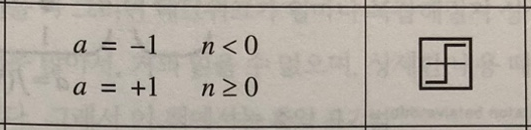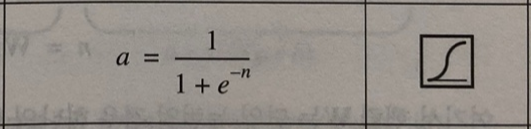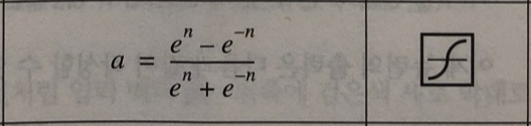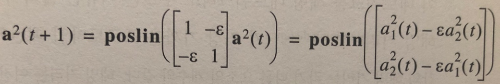Deep neural networks do the input-to-target mapping via a deep sequence of simple data tranformations (layers). This transformation implemented by a layer is parameterised by its weights. Weights are also sometimes called the parameters of a layer.
Learning means finding a set of values for the weights of all layers in a network.
The network will correctly map the inputs to their associated targets only if the weights are reasonable.
To control the output of a neural network, we need to be able to measure how far this output is from what we expected. This is the job of the loss function of the network. The loss function is also sometimes called the objective function or cost function.
The loss function takes the predictions of the network and the true target and computes a distance score, capturing how well the network has done.
The fundamental trick in deep learning is to use this score as a feedback signal to adjust the value of the weights a little, in a direction that will lower the loss score. This adjustment is the job of the optimiser, which implements what's called the backpropagation algorithm, which is the central algorithm in deep learning.
With every example the network processes, the weights are adjusted a little in the correct direction, and the loss score decreases. This is the training loop.
선형 연상 메모리에 대한 헵 학습의 성능 분석 시 프로토타입 벡터 (p_q) 가 직교하면서 단위 길이를 갖는 정규직교 (orthonormal) 인 경우와 단위 길이를 갖지만 직교하지 않는 경우를 나눠서 살펴볼 수 있다.
정규직교인 경우: p_k 가 네트워크 입력이면 네트워크 출력은 다음과 같이 계산된다. $$ a=Wp_k=(\sum_{q=1}^{Q}t_qp_q^T)p_k=\sum_{q=1}^{Q}t_q(p_q^Tp_k) $$ p_q 가 정규직교이기 때문에 다음과 같이 된다. $$ (p_q^Tp_k)=1, q=k $$ $$ (p_q^Tp_k)=0, q!=k $$ Identity matrix 가 되기 때문에 네트워크 출력은 다음과 같이 간단하게 작성될 수 있다. $$ a=Wp_k=t_k $$
단위 길이이지만, 직교가 아닌 경우: 벡터가 직교하지 않기 때문에 네트워크는 정확한 출력을 생성하지 않을 것이며, 오차의 크기는 프로토타입 입력 패턴 사이에 상관 관계의 크기에 따라 달라진다. $$ a=Wp_k=t_k+\sum_{q!=k}^{}t_q(p_q^Tp_k) $$ 우항의 시그마는 오차를 나타낸다.
학습 규칙 (learning rule) 은 네트워크의 가중치와 편향을 변경하는 방법을 의미한다. 학습 규칙은 크게
지도 학습 (supervised learning)
비지도 학습 (unsupervised learning)
강화 학습 (reinforcement learning)
으로 분류할 수 있다.
지도 학습은 훈련 집합 (training set) 과 같은 예시를 학습 규칙에 제공한다.
$$ \{p_1,t_1\}, \{p_2,t_2\}, ... , \{p_Q,t_Q\} $$
p는 네트워크 입력이며, t는 대응되는 정확한 출력 (목표) 이다.
각 입력을 네트워크에 적용해서 네트워크 출력과 목표를 비교한다.
네트워크 출력이 목표에 가까워지도록 학습 규칙을 사용해 네트워크의 가중치와 편향을 조정한다.
지도 학습에서 이진 분류로 결과가 나올 경우 그 출력을 discrete output 이라고 하며, classification problem 이 이에 해당한다. 시간의 흐름에 따라 값을 예측하는 경우 그 출력을 continuous output 이라고 하며, regression problem 이 이에 해당한다.
지도 학습은 훈련 알고리즘 (training algorithm) 에 네트워크 입력에 대한 목표를 제공하지만, 강화 학습은 등급 (또는 점수) 을 부여한다. 등급은 연속적인 입력에 대한 네트워크 성능 척도다. 강화 학습에는 액션에 따른 보상 (reward) 이 주어지며, 보상에 따라 액션을 바꿔가며 더 나은 결과를 유도한다.
비지도 학습은 사용 가능한 목표 출력이 없고, 네트워크 입력에 대한 반응만으로 가중치와 편향을 변경한다. 대부분의 비지도 학습 알고리즘은 군집화 연산을 수행해서 입력 패턴을 한정된 수의 클래스로 범주화 하도록 학습한다.
예를 들어 weight = 3, p = 2, b = -1.5 일 때, a = f(3 * 2 - 1.5) = f(4.5) 로 출력된다.
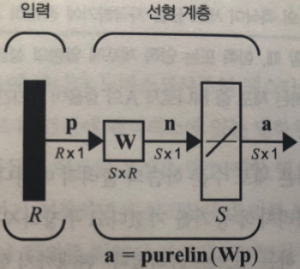
다중 입력 뉴런 (Multiple input neuron)
입력이 2개 이상인 뉴런
a = f(W * p + b)
Weight: 가중치 행렬
개별 입력 p1, p2,... 에 대응하는 각각의 가중치 w 존재
일 때
로 표현할 수 있다.
계층
출력 계층 (output layer)
은닉 계층(hidden layer)
1~2번째 은닉계층과 3번째 출력계층으로 이뤄진 네트워크
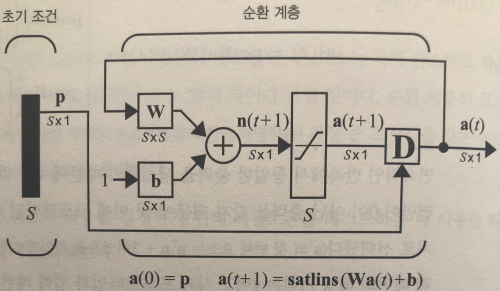
순환 계층 (recurrent layer)
순환망 (recurrent network) 은 피드백이 있는 네트워크이므로, 피드포워드 (feedforward) 네트워크보다 강력하며 시간적 행동을 보여줄 수 있다.
전달함수 종류
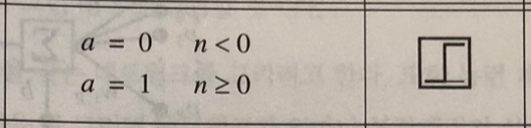
1. 하드 리밋 (Hard Limit)
2. 대칭 하드 리밋 (Symmetrical Hard Limit)
3. 선형 (Linear)
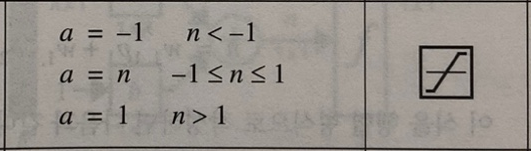
4. 포화 선형 (Saturating Linear)
5. 대칭 포화 선형 (Symmetric Saturating Linear)
6. 로그-시그모이드 (Log-Sigmoid)
7. 하이퍼볼릭 탄젠트 시그모이드 (Hyperbolic Tangent Sigmoid)
8. 양의 선형 (Positive Linear)
9. 경쟁 (Competitive)
입력 2개의 뉴런 파라미터가 $$ b=1.2, W=\begin{bmatrix} 3 & 2 \\ \end{bmatrix}, p=\begin{bmatrix} -5 & 6 \\ \end{bmatrix}^T $$ 인 경우 네트 입력은 $$ n=Wp+b=\begin{bmatrix} 3 & 2 \\ \end{bmatrix}\begin{bmatrix} -5 \\ 6 \end{bmatrix}+(1.2)=-1.8 $$ 로 계산되고, 뉴런 출력은
대칭 하드 리밋 전달 함수: $$ a=hardlims(-1.8)=-1 $$
포화 선형 전달 함수: $$ a=satlin(-1.8)=0 $$
하이퍼볼릭 탄젠트 시그모이드 전달 함수: $$ a=tansig(-1.8)=-0.9468 $$
등으로 구할 수 있다.
피드포워드 네트워크의 이진 패턴 인식에는 경계 값에 따라 분류를 하는 과정에서 애매한 경우 정확도가 떨어질 수 있는 문제가 있다. 이를 보완한 것이 해밍 (hamming) 네트워크와 홉필드 (hopfield) 네트워크이다.
해밍 네트워크는 피드포워드 계층과 순환 계층을 모두 이용한다.
피드포워드 계층에서는 프로토타입 벡터와 입력 벡터의 닮음 정도 (내적) 에 편향 벡터를 더해 값이 절대 음수가 되지 않게 함으로써 순환 계층이 적절히 작동하도록 한다. 순환 계층은 경쟁 계층으로, 피드포워드 계층 출력에 가중 행렬을 곱하는 과정을 반복한다. 가중 행렬은 아래와 같은 형태를 갖는다.