Natural Language Processing (NLP) is informed by a number of perspectives (disciplines contribute to NLP):
Computer/data science
Theoretical foundation of computation and practical techniques for implementation
Information science
Analysis, classification, manipulation, retrieval and dissemination of information
Computational Linguistics
Use of computational techniques to study linguistic phenomena
Cognitive science
Study of human information processing (perception, language, reasoning, etc.)
NLP adopts multiple paradigms:
Symbolic approaches
Rule-based, hand coded (by linguists/subject matter experts)
Knowledge-intensive
Statistical approaches
Distributional & neural approaches, supervised or unsupervised
Data-intensive
NLP applications:
Text categorisation
Media monitoring
Classify incoming news stories
Search engines
Classify query intent, e.g. search for 'LOG313'
Spam detection
Machine translation
Fully automatic, e.g. Google translate
Semi-automated
Helping human translators
Text summarisation : to manage information in overload, we need to abstract it down to the most important elements or summarise it
Summarisation
Single-document vs. multi-document
Search results
Word processing
Research/analysis tools
Dialog systems
Chatbots
Smartphone speakers
Smartphone assistants
Call handling systems
Travel
Hospitality
Banking
Sentiment Analysis : identify and extract subjective information
Several sub-tasks:
Identify polarity e.g. of movie reviews e.g. positive, negative, or neutral
Identify emotional states e.g. angry, sad, happy, etc
Subjectivity/objectivity identification e.g. “fact” from opinion
Feature/aspect-based : differentiate between specific features or aspects of entities
Text mining
Analogy with Data Mining
Discover or infer new knowledge from unstructured text resources
A<->B and B<->C
Infer A<->C? e.g. link between migraine headaches and magnesium deficiency
Applications in life sciences, media/publishing, counter terrorism and competitive intelligence
Question answering
Going beyond the document retrieval paradigm : provide specific answers to specific questions
Natural language generation
Speech recognition & synthesis
…and lots more
History of NLP
Foundational Insights: 1940s and 1950s
Two foundational paradigms: 1. The automaton, which is the essential information processing unit 2. Probabilistic or information-theoretic models
The automaton arose out of Turing’s (1936) model of algorithmic computation
Chomsky (1956) considered finite state machines as a way to characterise a grammar : he was one of the first people to use these ideas
Shannon (1948) borrowed the concept of entropy from thermodynamics : Entropy is a measure of uncertainty (as entropy approaches 1.0, uncertainty increases)
As a way of measuring the information content of a language
Measured of the entropy of English by using probabilistic techniques based on the concept of entropy
Two camps: 1960s and 1970s
Speech and language processing split into two paradigms: 1. Symbolic: - Chomsky and others on parsing algorithms - Artificial intelligence (1956) work on reasoning and logic - Early natural language understanding (NLU) systems: - Single domains pattern matching - Keyword search - Heuristics for reasoning 2. Statistical (stochastic) - Mosteller and Wallace (1964) applied Byesian methods to the problem of authorship attribution on The Federalist Papers
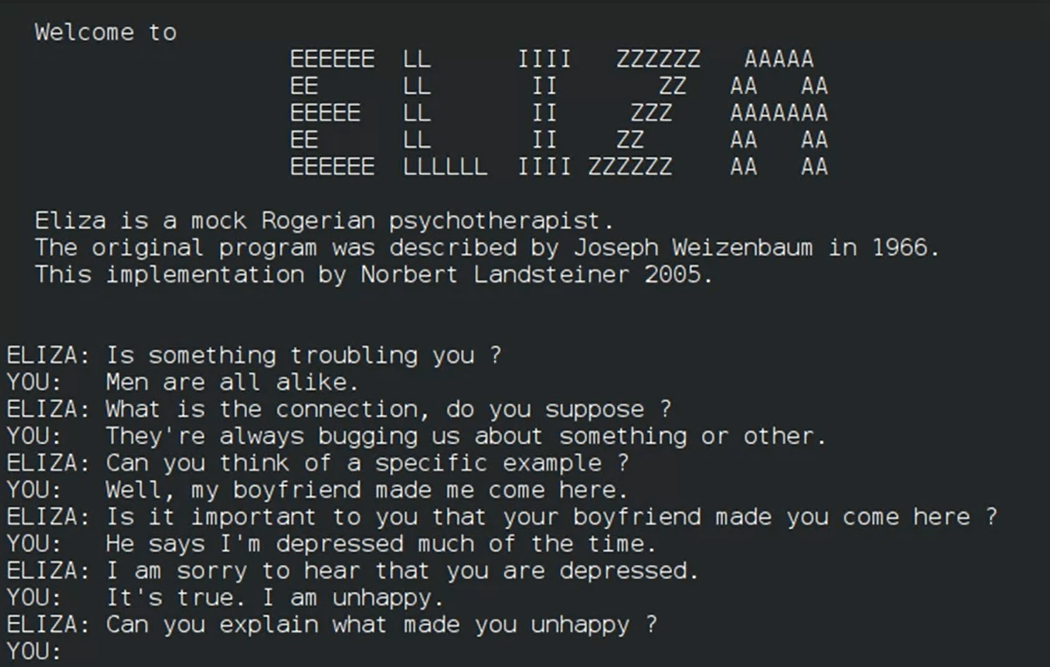
Early NLP systems : ELIZA and SHRDLU were the highly influential early NLP systems
ELIZA
Wiezenbaum 1966
Pattern matching (ELIZA used elementary keyword spotting techniques)
First chatbot
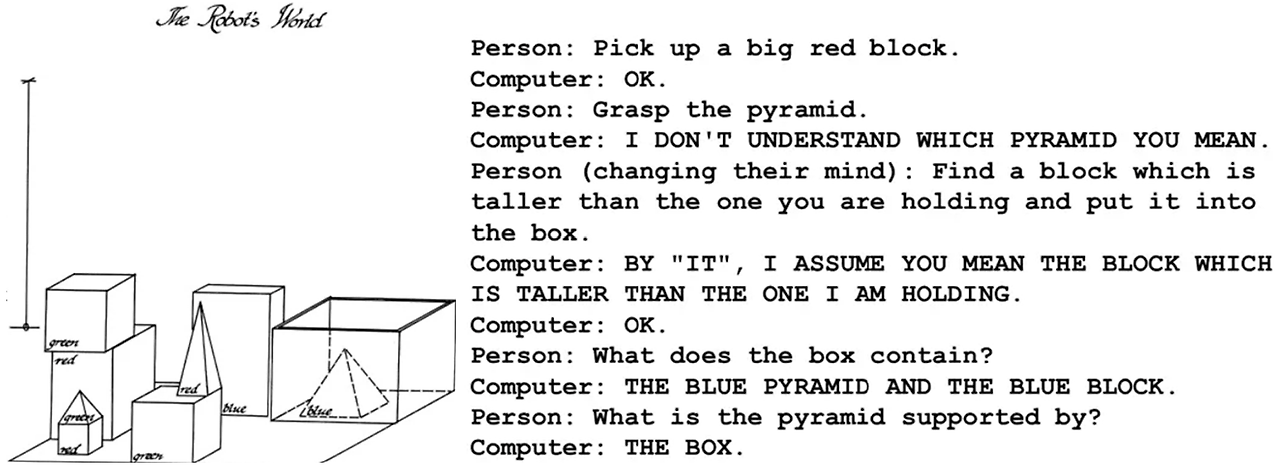
SHRDLU
Winograd 1972
Natural language understanding
Comprehensive grammar of English
They created this imaginary world called the block’s world (simulated a robot embedded in a world of toy blocks). The user could interact with this block’s world by asking questions and giving commands.
Further developments in the 1960s
First text corpora (corpora is plural of corpus)
The Brown corpus: a one-million-word collection of samples from 500 written texts from different genres (newspaper, novels, non-fiction, academic, etc.), assembled at Brown University in 1963-64 (Kuˇcera and Francis, 1967; Francis, 1979; Francis and Kuˇcera, 1982), and William S. Y. Wang’s 1967 DOC (Dictionary on Computer)
Empiricism: 1980s and 1990s : The rise of the WWW emphasised the need for language-based information retrieval and information extraction.
The return of two classes of models that had lost popularity: 1. Finite-state models: - Finite-state morphology by Kaplan and Kay (1981) and models of syntax by Church (1980) 2. Probabilistic and data-driven approaches: - From speech recognition to part-of-speech tagging, parsing and semantics
Model evaluation
Quantitative metrics, comparison of performance with previous published research
Regular competitive evaluation exercises such as the Message Understanding Conferences (MUC)
The rise of machine learning: 2000s : Large amounts of spoken and written language data became available, including annotated collections e.g. Penn Treebank (Marcus et al. 1993)
Traditional NLP problems, such as parsing and semantic analysis, became problems for supervised learning
Unsupervised statistical approaches began to receive renewed attention
Statistical approaches to machine translation (Brown et al., 1990; Och and Ney, 2003) and topic modelling (Blei et al., 2003) demonstrated that effective applications could be constructed from systems trained on unannotated data
Cost and difficulty of producing annotated corpora became a limiting factor for supervised approaches
Ascendance of deep learning: 2010s onwards
Deep learning methods have become pervasive in NLP and AI in general
Advances in technology such as GPUs developed for gaming
Plummeting costs of memory
Wide availability of software platforms
Classic ML methods require analysts to select features based on domain knowledge
Deep learning introduced automated feature engineering: generated by the learning system itself
Collobert et al (2011) applied convolutional neural nets (CNNs) to POS tagging, chunking, NE tags and language modelling
CNNs unable to handle long-distance contextual information
Recurrent neural networks (RNNs) process items as a sequence with a "memory" of previous inputs' : The method is very useful for what we call sequence labelling tasks.
Applicable to many tasks such as:
Word-level: named entity recognition, language modelling
Sentence-level: sentiment analysis, selecting responses to messages
Language generation for machine translation, image captioning, etc.
RNNs are supplemented with long short-term memory (LSTM) or gated recurrent units (GRUs) to improve training performance (the 'vanishing gradient problem').