Words with similar contexts have similar meanings
- Zellig Harris (1954): 'If A and B have almost identical environments, we say that they are synonyms' (e.g. doctor|surgeon (patient, hospital, treatment, etc)
→ This notion is referred to as the distributional hypothesis
Distributional hypothesis
- Is concerned with the link between similar distributions and similar meanings
- Assumes words with similar contexts have similar meanings
Distributional models are based on a co-occurrence matrix
- Term-document matrix
- Term-term matrix

Overall matrix is |V| by |D|
- Similar documents have similar words: represented by the column vectors
- Similar words occur in similar documents: represented by the row vectors
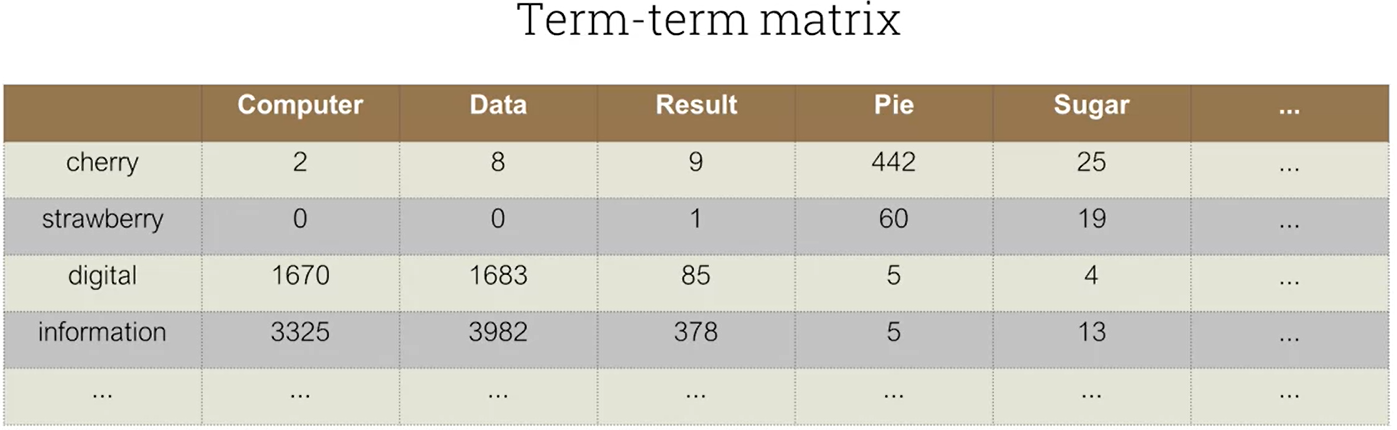
Overall matrix is |V| by |V|
- Represents co-occurrences in some corpus
- Context is usually restricted to a fixed window (e.g. +/- 4 words)
- Similar terms have similar vectors
Problems with term-term matrices:
- Term-term matrices are sparse
- Term vectors are long |V|
- Most entries are zero
Doesn't reflect underlying linguistic structure: 'food is bad' and 'meal was awful'
Word embeddings
- Represent words as low-dimensional vectors
- Capture semantic and syntactic similarities between words (e.g. food|meal, bad|awful, etc)
- Typically have 50-300 dimensions rather than |V| (compared to the vast vocabulary size)
- Most vector elements are non-zero
Benefits
- Classifiers need to learn far fewer weights
→ significantly reduce the number of parameters for classifiers - Improve generalisation and prevent overfitting
- Capture semantic relationships like synonymy
Word2Vec software package: Static embeddings (unlike BERT or ELMo)
- Key idea
- Predict rather than count
- Binary prediction task: 'Is word x likely to co-occur with word y?'
- Use the learned classifier weights
- Running text is the training data
- Basic algorithm (skip-gram with negative sampling)
- Treat neighbouring context words as positive samples
- Treat other random words in the vocabulary (V) as negative samples
→ negative samples are randomly selected words that did not appear in the context window - Train a logistic regression classifier to distinguish these classes
- Use learned weights as embeddings
The benefits of using word embeddings compared to traditional vector representations:
- They often better generalisation capabilities
- They are more compact


'NaturalLanguageProcessing > Concept' 카테고리의 다른 글
| (w07) Lexical semantics (0) | 2024.05.22 |
|---|---|
| (w06) N-gram Language Models (0) | 2024.05.14 |
| (w04) Regular expression (0) | 2024.04.30 |
| (w03) Text processing fundamentals (0) | 2024.04.24 |
| (w02) NLP evaluation -basic (0) | 2024.04.17 |