Data representations for neural networks
- Scalars (rank-0 tensors)
e.g. np.array(2) - Vectors (rank-1 tensors or 1D tensor)
e.g. np.array([2, 3]) - Matrices (rank-2 tensors or 2D tensor)
e.g. np.array([[2, 3], [4, 5]]) - Rank-3 (3D tensor)
e.g. np.array([[[2, 3, 4], [5, 6, 7]], [[8, 9, 10], [11, 12, 13]], [[14, 15, 16], [17, 18, 19]]])
features: 2, width: 3, samples: 1
Tensors are a generalisation of matrices to an arbitrary number of dimensions (a dimension is often called an axis).
Ranks are the number of axes of a tensor.
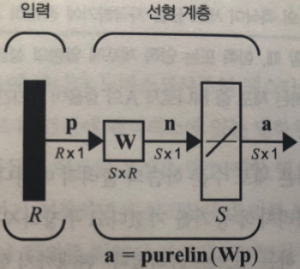
Tensor operations
- Build a model by stacking Dense layers on top of each other
- Hidden layer: tensorflow.keras.layers.Dense(512, activation="relu")
- This function is as follows: relu(dot(input, W) + b)
- dot is a dot product between the input tensor and a tensor named W
- + is an addition between the resulting matrix and a vector b
- "relu" stands for "rectified linear unit", and relu(x) is equivalent to max(x, 0)
- "relu" activation is usually used in the hidden layer, especially in the first layer
- The number of units (neurons), 512 in this case, should be determined based on the complexity of the data. It should not be random.
- Output layer: tensorflow.keras.layers.Dense(10, activation="softmax")
- This last layer is a 10-way softmax classification layer, which means it will return an array of 10 probability scores (summing to 1).
- Hidden layer: tensorflow.keras.layers.Dense(512, activation="relu")
- Make the model ready for training at the compilation step
- optimizer: The mechanism through which the model will update itself based on the training data it sees, to improve its performance.
- loss: How the model will be able to measure its performance on the training data, and thus how it will be able to steer itself in the right direction. The purpose of loss functions is to compute the quantity that a model should seek to minimise during training.
- metrics: This function is used to judge the performance of a model (monitor during training and testing).
- Fit the model to its training data
- epochs
- batch_size



The three screenshots are excerpts from the code available at https://github.com/we1c0me2s0rapark/UoL-MLNN/blob/main/MNIST.ipynb
In the above case, given the shape of the training data as (60000, 784), the number of gradient updates is calculated as 2345, obtained from ((60000/128) * 5).
'ArtificialIntelligence > TensorFlow' 카테고리의 다른 글
| NumPy array vs. TensorFlow tensor (0) | 2024.01.23 |
|---|