Assignable or not
While NumPy arrays are flexible and can be changed (mutable), TensorFlow tensors are fixed (immutable). This means that it is possible to directly modify the values of NumPy arrays, but changing the values of TensorFlow tensors after their creation is not allowed.
For example, the following NumPy array allows itself to be assigned:

In contrast, a TensorFlow tensor cannot be revised as follows:
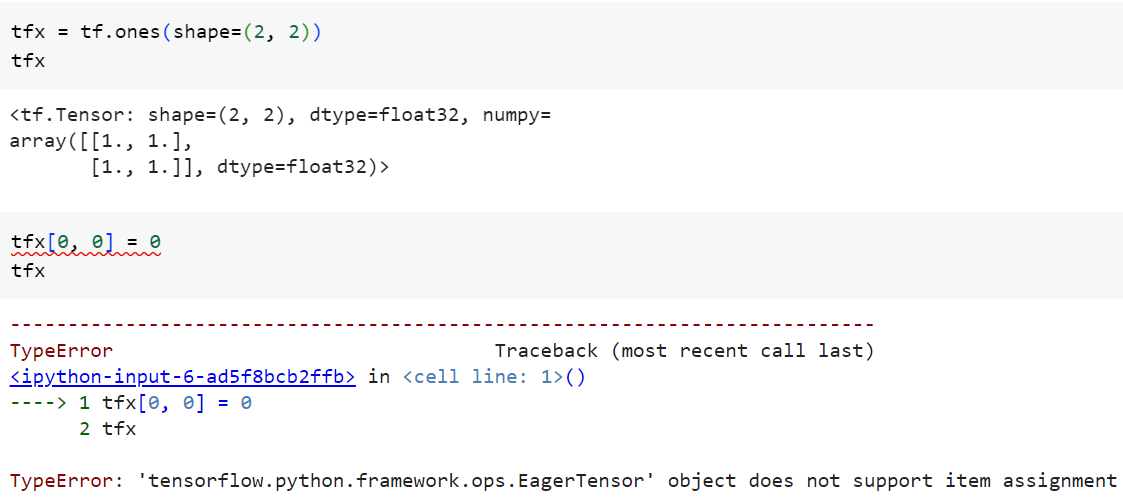
To update TensorFlow tensors, the tf.Variable class can be used.

Gradient Computation Capabilities
NumPy can't retrieve the gradient of any differentiable expression for any of its inputs. To apply some computation to one or several input tensors and retrieve the gradient of the result with respect to the inputs, just open a GradientTape scope as below:

When dealing with a constant tensor, it needs to be explicitly marked for tracking by calling watch() on it. This is because storing the information required to compute the gradient of anything with respect to anything would be too expensive to do preemptively. The following example utilises watch() to avoid wasting resources, ensuring that the GradientTape knows what to monitor:

The GradientTape is capable of computing second-order gradients (the gradient of a gradient).
- The gradient of the position of an object with regard to time is the speed of that object.
- The second-order gradient is its acceleration.
Here is an example below:

'ArtificialIntelligence > TensorFlow' 카테고리의 다른 글
| Basic functions of Keras within TensorFlow (0) | 2024.01.18 |
|---|