Quick Sort is quite easy to be implemented and has a good average performance (N log N).
However, this algorithm is not very stable since the performance in the worst case is N * N (N^2).
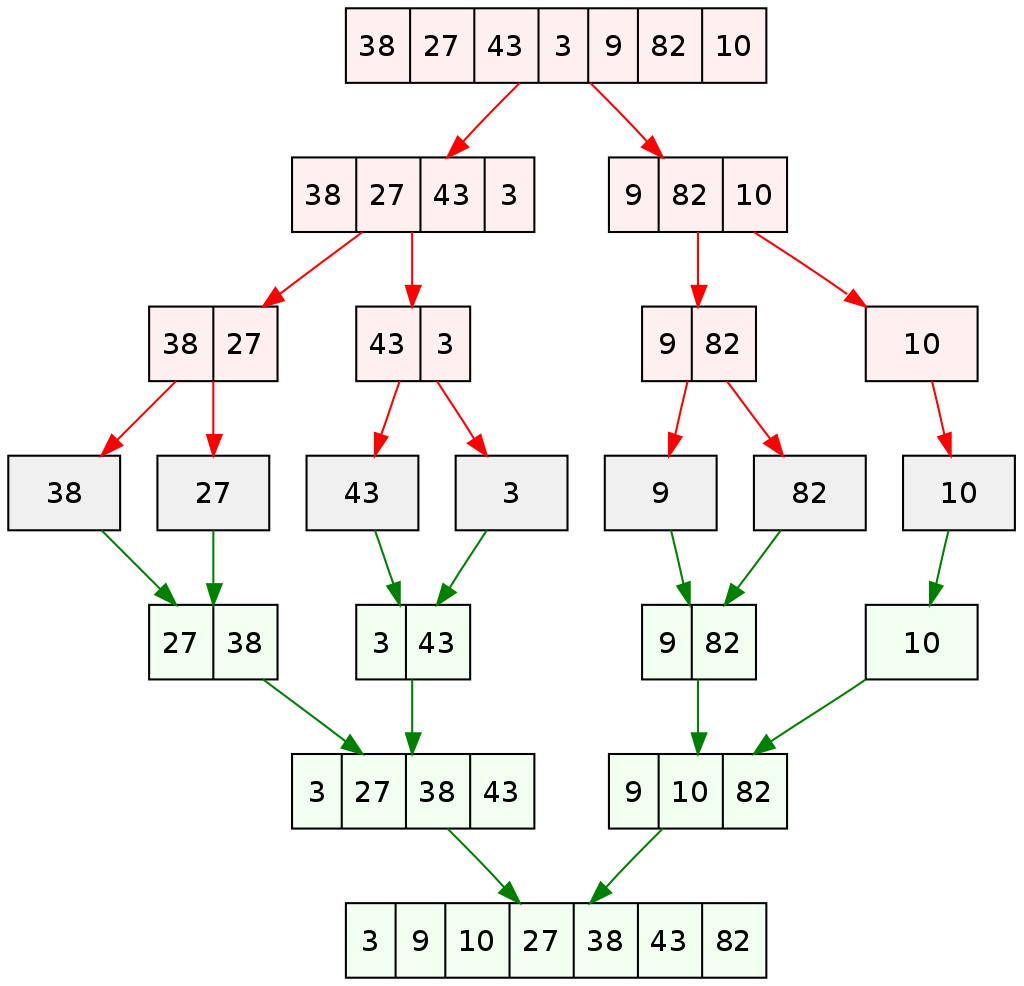
The basic idea of Quick Sort is to apply "divided-and-conquer" paradigm like Merge Sort, which works based on the mechanism to partition the file into two parts, then recursively sort the parts independently. The detailed procedure is as follows:
- Choose a pivotal (central) element
For example, first, last or middle element - Elements on either side are then moved so that the elements on one side of the pivot are smaller and those on the other side are larger
- Apply the above procedure to the two parts until the whole file is sorted in the proper order
2021.08.24 - [Algorithms] - [Sorting] Merge Sort 합병 정렬
# Example
array = { 10, 80, 30, 90, 40, 50, 70 };
- Pivot: 70
array_left = { 10, 30, 40, 50 }
array_right = { 90, 80 } - Pivot: 50 and 80 respectively
array_left = { 10, 30, 40 }
array_right = { 90 } - Pivot: 40 and null
array_left = { 10, 30 }
array_right = { } - Pivot: 30 and null
array_left = { 10 }
array_right = { } - Finally, there is only one value to be considered: 10
result = { 10, 30, 40, 50, 70, 80 };
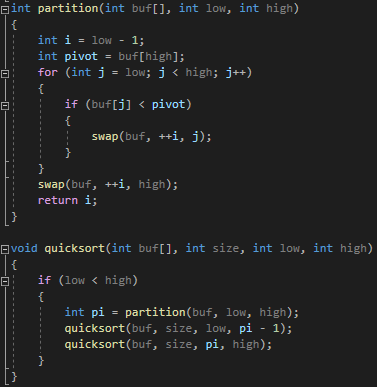
# Pseudocode
arr: original array
n: array size
pi: mid index
pivot: pivot value
i: index
quick_sort(low, high)
n := buf.size()
if low is less than high
pi := partition(low, high)
quick_sort(low, pi - 1)
quick_sort(pi + 1, high)
end
partition(low, high)
pivot := buf[high]
i := low - 1
for j is low to high - 1 do:
if buf[j] is less than pivot
swap(++i, j)
end for
swap(++i, high)
end
# Computation in C
# Time Complexity
- Worst complexity: O(n²)
- Average complexity: O(n*log(n))
- Best complexity: O(n*log(n))
'Algorithms' 카테고리의 다른 글
| [Sorting] Insertion Sort 삽입정렬 (0) | 2021.08.24 |
|---|---|
| [Sorting] Bubble Sort 버블정렬 (0) | 2021.08.24 |
| [Sorting] Heap Sort 힙 정렬 (0) | 2021.08.24 |
| [Sorting] Merge Sort 합병 정렬 (0) | 2021.08.24 |
| [Sorting] Shell Sort 셀 정렬 (0) | 2021.08.24 |